
前言
本笔记是为使用Dify开发微信聊天可视化网页的工作流 ,如果不清楚的同学可以看我之前的文章上手Dify(1)---Dify的安装与使用并接入DeepSeek - 秦绍鹏的笔记。
开发这个工作流的初衷是某个群友在群里说了一嘴其他博主使用AI将微信聊天记录转换为可视化,但是那个教程比较麻烦,并且还要自己去创建文件最后生成一个html网页,我就想能不能做一个dify可视化,最终做出来了然后记录一下。
由于我自己本身表达能力有限,所以该教程可能有的地方说的不够清晰,欢迎大家指正。
搭建步骤
新建应用,选择工作流。
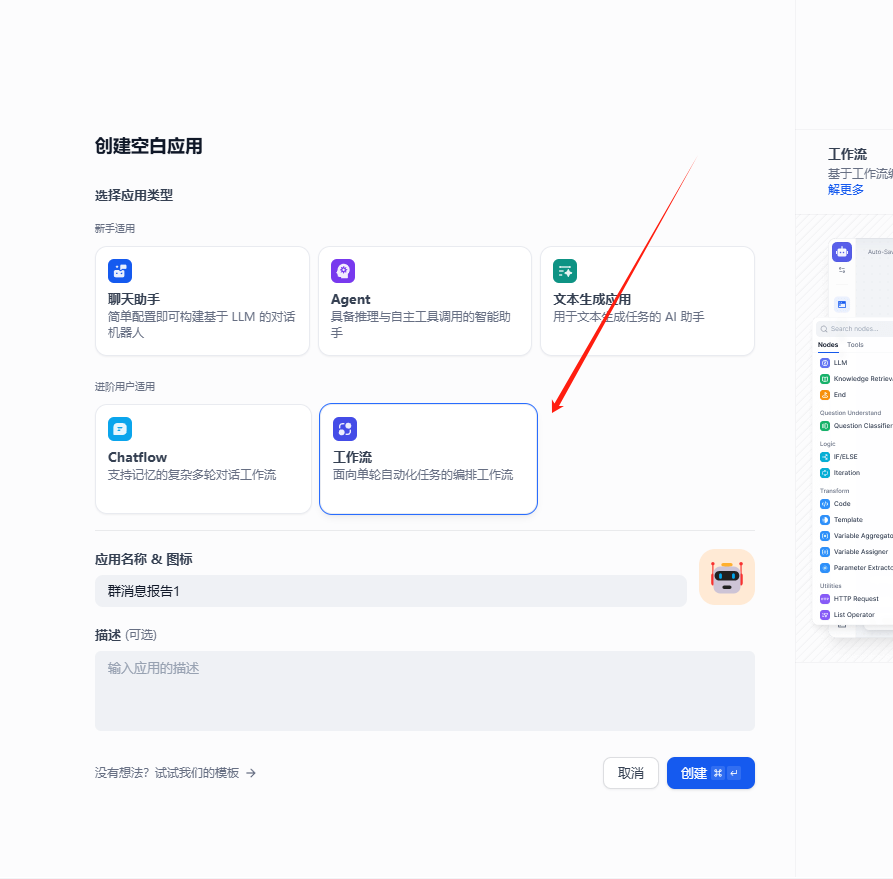
选中第一个
节点,然后点击创建变量。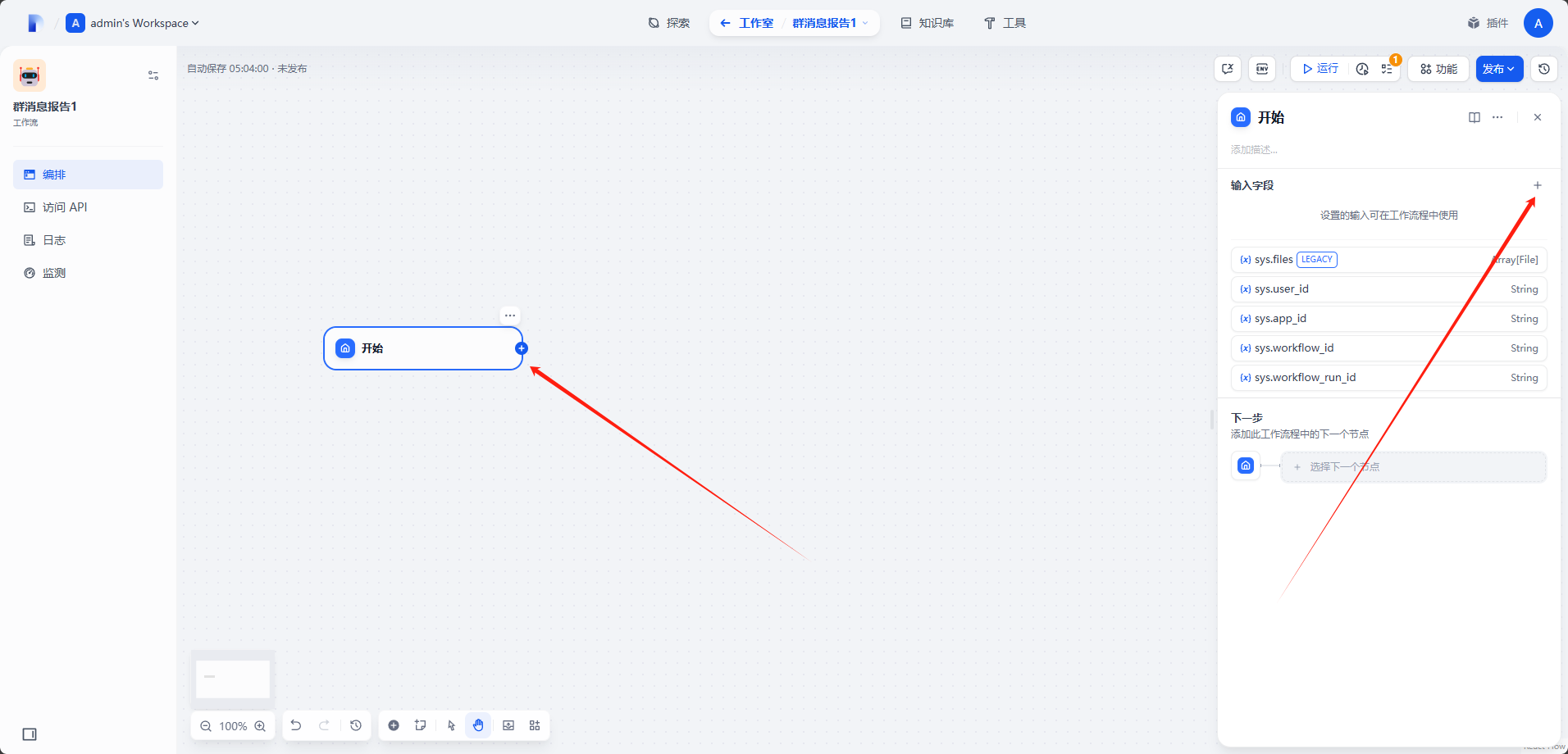
首先创建一个
文件类型变量,填写相应的变量名称和显示名称,设置为单文件,添加其他类型.json,上传文件类型可以不用管。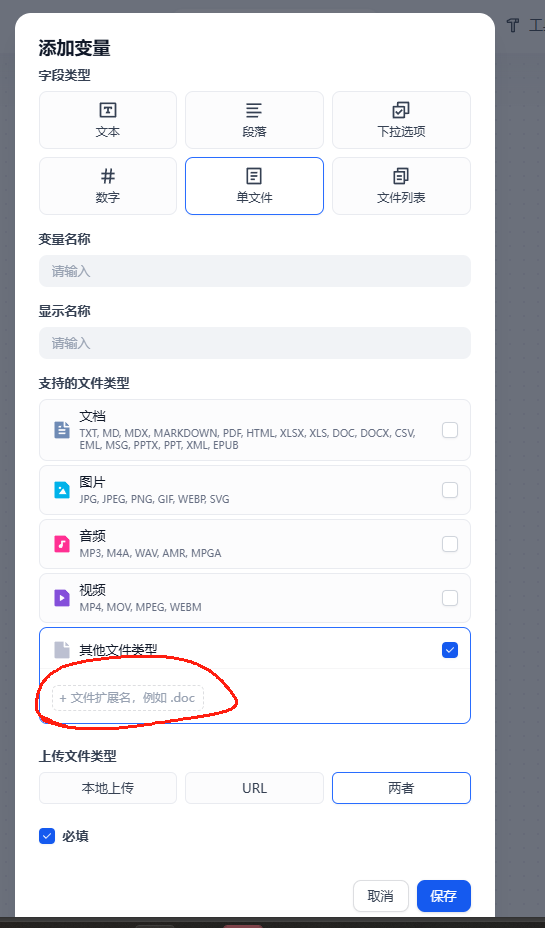
之后创建
文档提取器节点,将输入变量设置为刚才设置的json变量。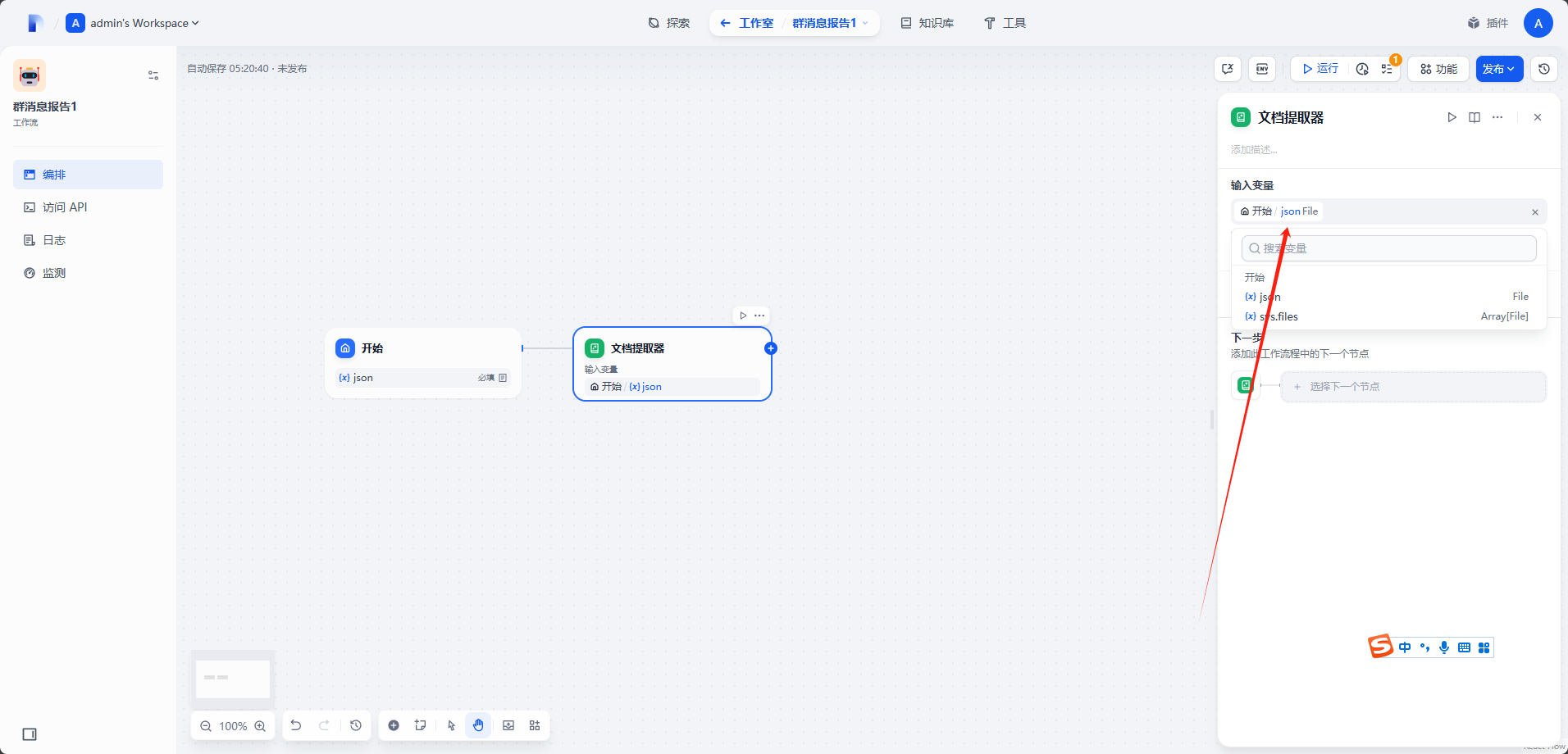
之后再创建
LLM节点使用模型可自选。点击
添加消息。
之后把下面的提示词放到
SYSTEM内容框里面。
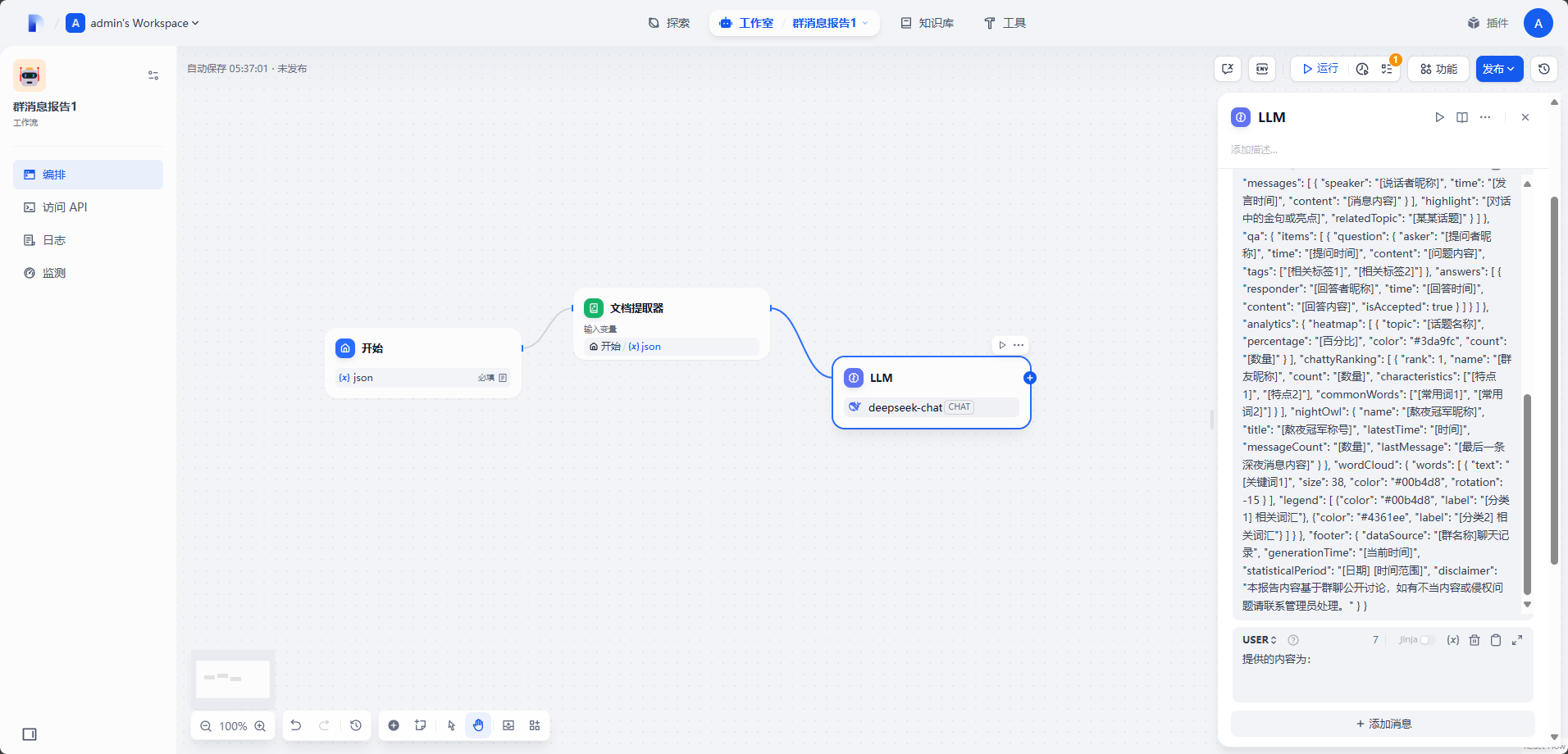
从内容中提取出以下信息,可以根据内容多少进行列表扩展或增加,请仔细思索怎么填充内容,如果没有给到合理的名称或其他内容,就以合理的方式思考并添加。 - 最后的输出值使用严格的json格式 - 不要私自添加json块或减少json块 - 内容中不要使用换行符,如果内容原本有多个换行符,删掉原本多余的的换行符,只保留一个换行符再加入进去。 - 内容中如果有很奇怪的字符,比如'\'或'\\'影响代码编译的字符,删除原本的字符再加入进去。 { "header": { "title": "[群名称]报告", "date": "[日期]", "metaInfo": { "totalMessages": "[数量]", "activeUsers": "[数量]", "timeRange": "[时间范围]" } }, "sections": { "hotTopics": { "items": [ { "name": "[热点话题名称]", "category": "[话题分类]", "summary": "[简要总结(50-100字)]", "keywords": ["[关键词1]", "[关键词2]"], "mentions": "[次数]" } ] }, "tutorials": { "items": [ { "type": "[TUTORIAL | NEWS | RESOURCE]", "title": "[分享的教程或资源标题]", "sharedBy": "[昵称]", "time": "[时间]", "summary": "[内容简介]", "keyPoints": ["[要点1]", "[要点2]"], "url": "[URL]", "domain": "[域名]", "category": "[分类]" } ] }, "importantMessages": { "items": [ { "time": "[消息时间]", "sender": "[发送者昵称]", "type": "[NOTICE | EVENT | ANNOUNCEMENT | OTHER]", "priority": "[高|中|低]", "content": "[消息内容]", "fullContent": "[完整通知内容]" } ] }, "dialogues": { "items": [ { "type": "[DIALOGUE | QUOTE]", "messages": [ { "speaker": "[说话者昵称]", "time": "[发言时间]", "content": "[消息内容]" } ], "highlight": "[对话中的金句或亮点]", "relatedTopic": "[某某话题]" } ] }, "qa": { "items": [ { "question": { "asker": "[提问者昵称]", "time": "[提问时间]", "content": "[问题内容]", "tags": ["[相关标签1]", "[相关标签2]"] }, "answers": [ { "responder": "[回答者昵称]", "time": "[回答时间]", "content": "[回答内容]", "isAccepted": true } ] } ] }, "analytics": { "heatmap": [ { "topic": "[话题名称]", "percentage": "[百分比]", "color": "#3da9fc", "count": "[数量]" } ], "chattyRanking": [ { "rank": 1, "name": "[群友昵称]", "count": "[数量]", "characteristics": ["[特点1]", "[特点2]"], "commonWords": ["[常用词1]", "[常用词2]"] } ], "nightOwl": { "name": "[熬夜冠军昵称]", "title": "[熬夜冠军称号]", "latestTime": "[时间]", "messageCount": "[数量]", "lastMessage": "[最后一条深夜消息内容]" } }, "wordCloud": { "words": [ { "text": "[关键词1]", "size": 38, "color": "#00b4d8", "rotation": -15 } ], "legend": [ {"color": "#00b4d8", "label": "[分类1] 相关词汇"}, {"color": "#4361ee", "label": "[分类2] 相关词汇"} ] } }, "footer": { "dataSource": "[群名称]聊天记录", "generationTime": "[当前时间]", "statisticalPeriod": "[日期] [时间范围]", "disclaimer": "本报告内容基于群聊公开讨论,如有不当内容或侵权问题请联系管理员处理。" } }把下面的提示词放到
USER内容框里面。
提供的内容为:效果为这样
之后编辑
USER内容框,将文档提取器的变量插入进去。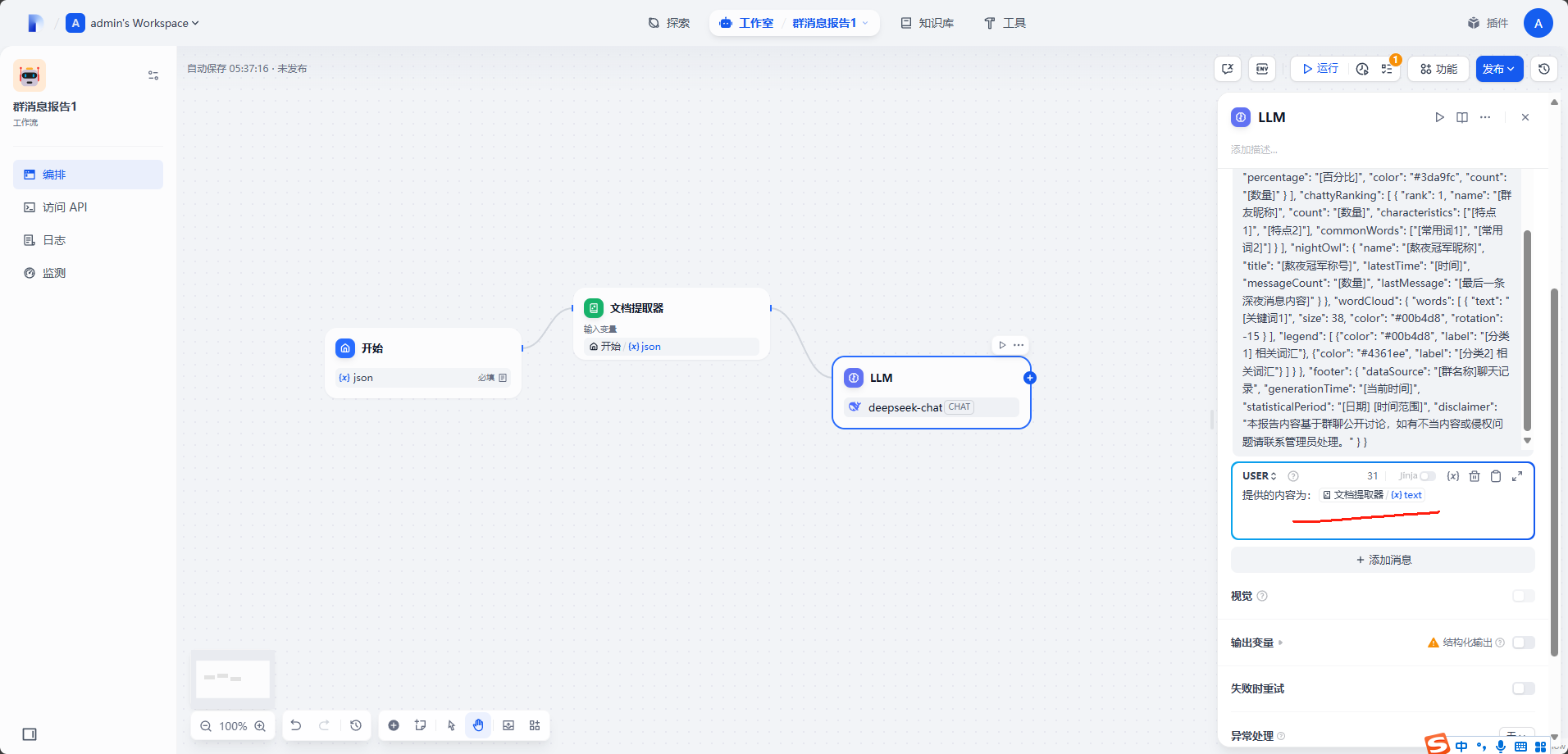
添加
条件分支节点。
该节点的作用是为了一会儿分流,可以选择生成JSON文件或者生成HTML文件。选中开始节点,添加
数字变量为isif取消勾选必填选项。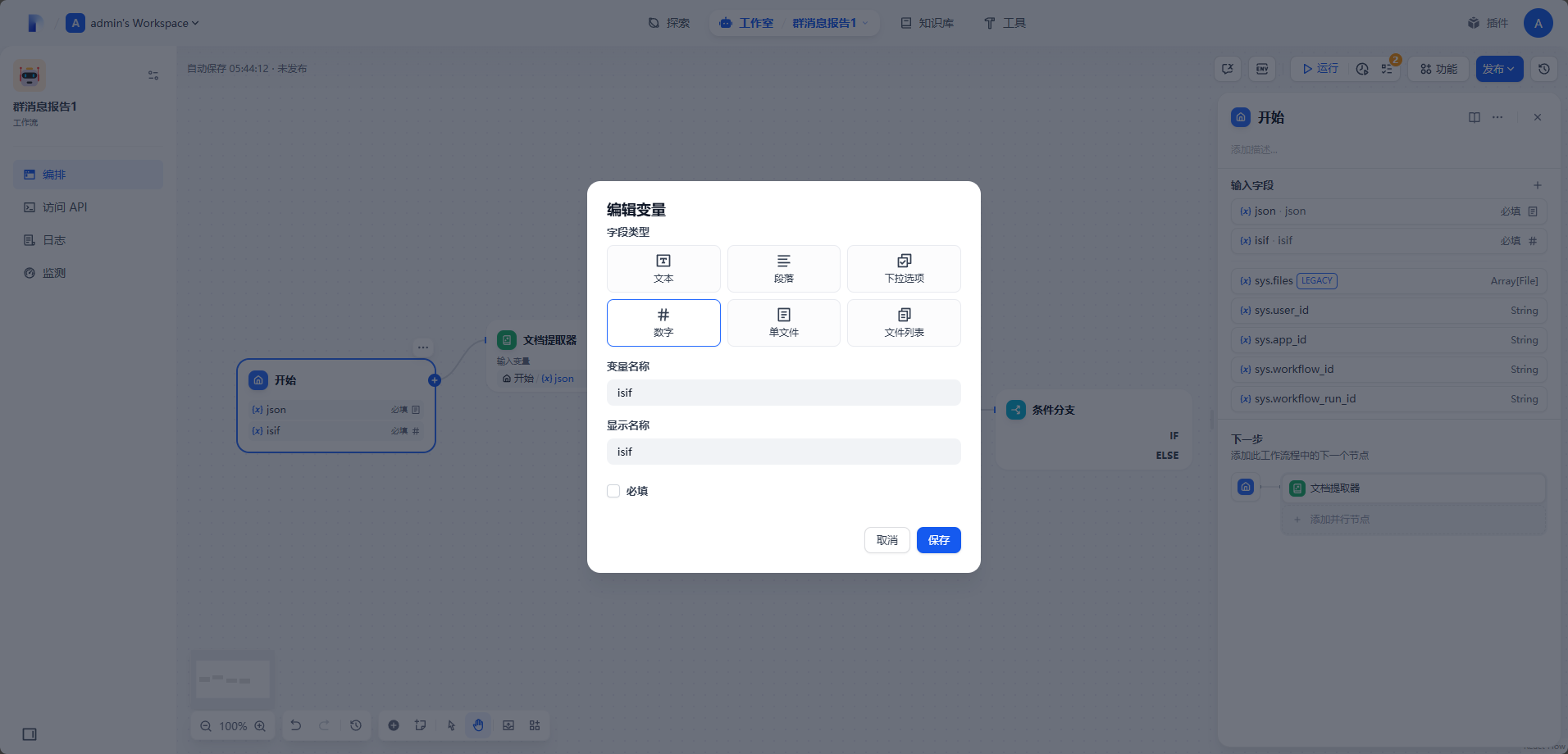
选中条件分支,点击
添加条件。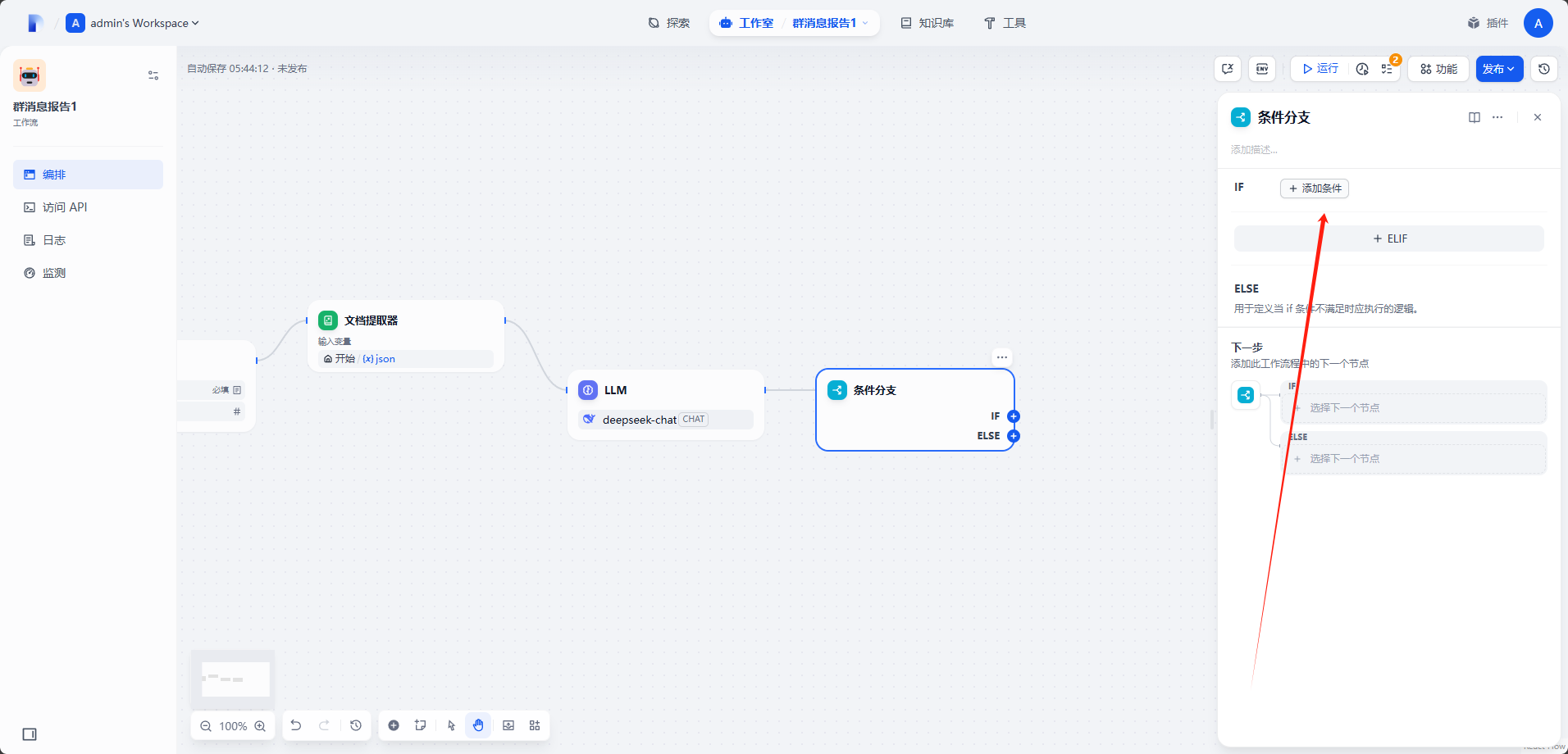
选择
isif变量,后面条件选择为空。选择下一节点。
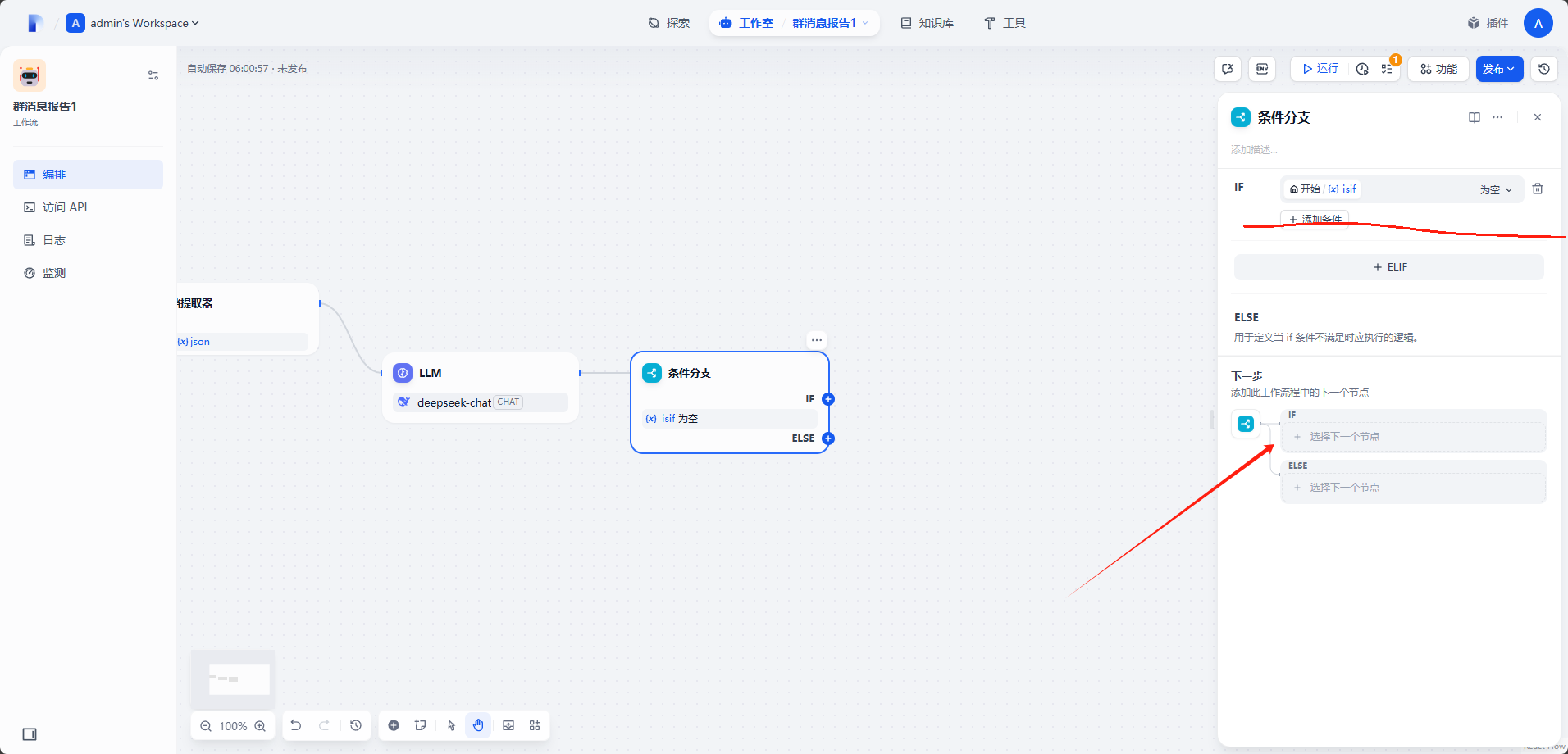
添加结束节点,变量选择
LLM输出。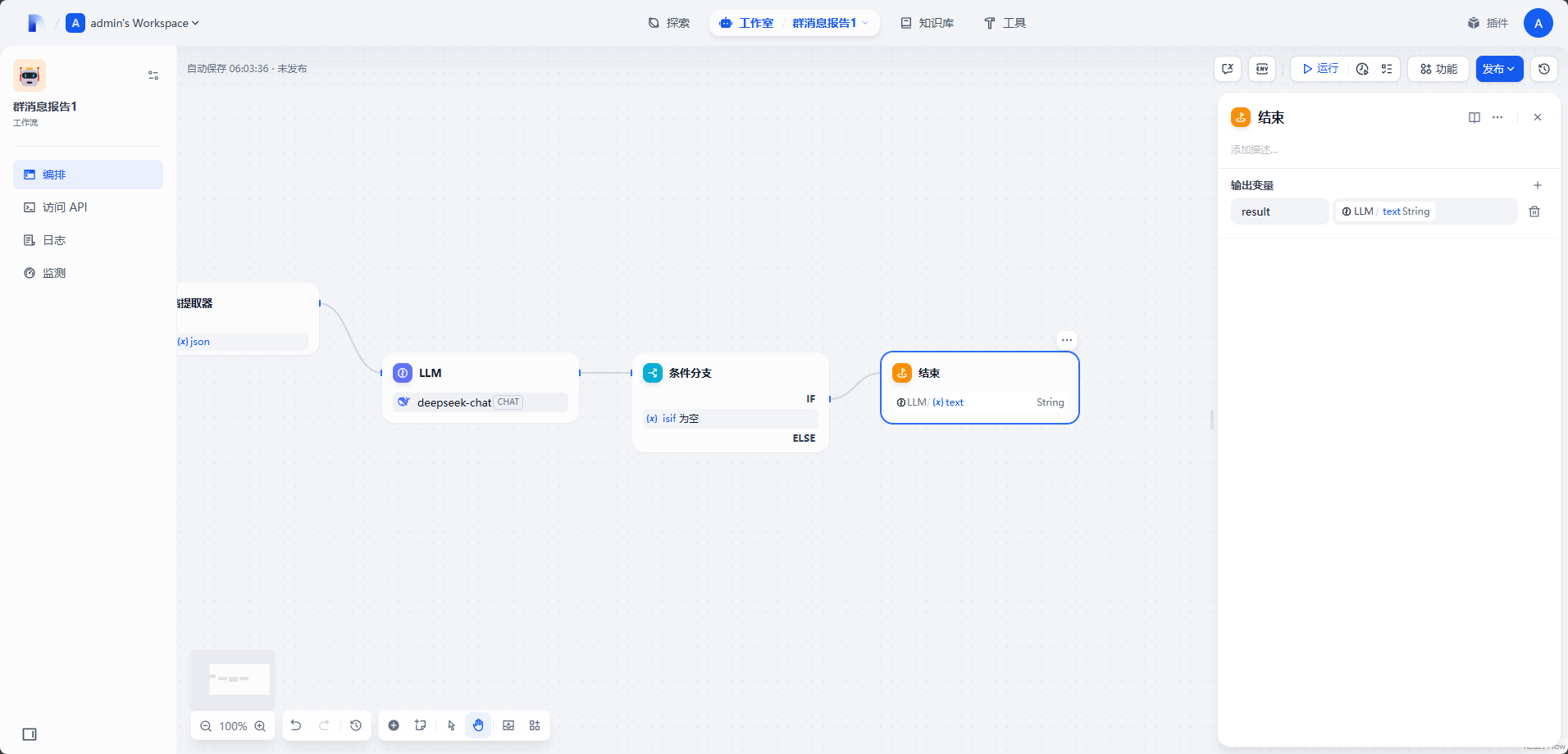
在
ELSE节点中添加代码执行节点设置输入变量,输出变量。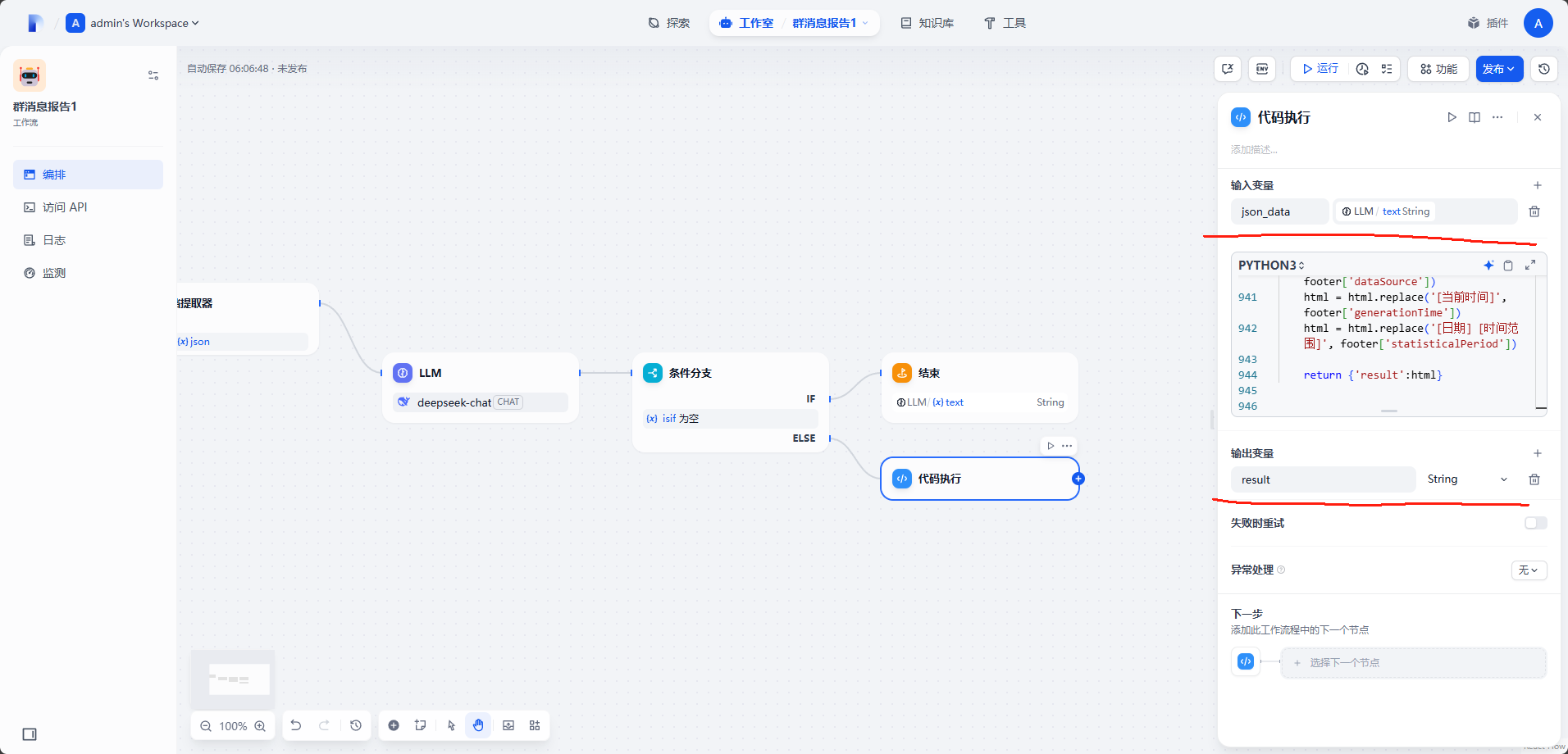
并复制以下
代码片段到内容区。import json import re def main(json_data): # 加载模板 html = """ <!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <title>[群/用户名称]日报 - [日期]</title> <style> /* 严格定义的CSS样式,确保风格一致性 */ :root { --bg-primary: #0f0e17; --bg-secondary: #1a1925; --bg-tertiary: #252336; --text-primary: #fffffe; --text-secondary: #a7a9be; --accent-primary: #ff8906; --accent-secondary: #f25f4c; --accent-tertiary: #e53170; --accent-blue: #3da9fc; --accent-purple: #7209b7; --accent-cyan: #00b4d8; } * { margin: 0; padding: 0; box-sizing: border-box; } body { font-family: 'SF Pro Display', 'Segoe UI', Roboto, Oxygen, Ubuntu, Cantarell, 'Open Sans', sans-serif; background-color: var(--bg-primary); color: var(--text-primary); line-height: 1.6; font-size: 16px; width: 1200px; margin: 0 auto; padding: 20px; } header { text-align: center; padding: 30px 0; background-color: var(--bg-secondary); margin-bottom: 30px; } h1 { font-size: 36px; font-weight: 700; color: var(--accent-primary); margin-bottom: 10px; } .date { font-size: 18px; color: var(--text-secondary); margin-bottom: 20px; } .meta-info { display: flex; justify-content: center; gap: 20px; } .meta-info span { background-color: var(--bg-tertiary); padding: 5px 15px; border-radius: 20px; font-size: 14px; } section { background-color: var(--bg-secondary); margin-bottom: 30px; padding: 25px; } h2 { font-size: 28px; font-weight: 600; color: var(--accent-blue); margin-bottom: 20px; padding-bottom: 10px; border-bottom: 2px solid var(--accent-blue); } h3 { font-size: 22px; font-weight: 600; color: var(--accent-primary); margin: 15px 0 10px 0; } h4 { font-size: 18px; font-weight: 600; color: var(--accent-secondary); margin: 12px 0 8px 0; } p { margin-bottom: 15px; } ul, ol { margin-left: 20px; margin-bottom: 15px; } li { margin-bottom: 5px; } a { color: var(--accent-blue); text-decoration: none; } a:hover { text-decoration: underline; } /* 卡片容器样式 */ .topics-container, .tutorials-container, .messages-container, .dialogues-container, .qa-container, .participants-container { display: grid; grid-template-columns: 1fr; gap: 20px; } /* 卡片样式 */ .topic-card, .tutorial-card, .message-card, .dialogue-card, .qa-card, .participant-item, .night-owl-item { background-color: var(--bg-tertiary); padding: 20px; } /* 话题卡片 */ .topic-category { display: inline-block; background-color: var(--accent-blue); color: var(--text-primary); padding: 3px 10px; border-radius: 15px; font-size: 14px; margin-bottom: 10px; } .topic-keywords { display: flex; flex-wrap: wrap; gap: 8px; margin: 10px 0; } .keyword { background-color: rgba(61, 169, 252, 0.2); padding: 3px 10px; border-radius: 12px; font-size: 14px; } .topic-mentions { color: var(--accent-cyan); font-weight: 600; } /* 教程卡片 */ .tutorial-type { display: inline-block; background-color: var(--accent-secondary); color: var(--text-primary); padding: 3px 10px; border-radius: 15px; font-size: 14px; margin-bottom: 10px; } .tutorial-meta { color: var(--text-secondary); margin-bottom: 10px; font-size: 14px; } .tutorial-category { margin-top: 10px; font-style: italic; color: var(--text-secondary); } /* 消息卡片 */ .message-meta { margin-bottom: 10px; } .message-meta span { margin-right: 15px; font-size: 14px; } .message-type { background-color: var(--accent-tertiary); color: var(--text-primary); padding: 3px 10px; border-radius: 15px; } .priority { padding: 3px 10px; border-radius: 15px; } .priority-high { background-color: var(--accent-secondary); } .priority-medium { background-color: var(--accent-primary); } .priority-low { background-color: var(--accent-blue); } /* 对话卡片 */ .dialogue-type { display: inline-block; background-color: var(--accent-purple); color: var(--text-primary); padding: 3px 10px; border-radius: 15px; font-size: 14px; margin-bottom: 10px; } .dialogue-content { background-color: rgba(255, 255, 255, 0.05); padding: 15px; margin-bottom: 15px; } .dialogue-highlight { font-style: italic; color: var(--accent-primary); margin: 10px 0; font-weight: 600; } /* 问答卡片 */ .question { margin-bottom: 15px; } .question-meta, .answer-meta { color: var(--text-secondary); margin-bottom: 5px; font-size: 14px; } .question-tags { display: flex; flex-wrap: wrap; gap: 8px; margin-top: 10px; } .tag { background-color: rgba(114, 9, 183, 0.2); padding: 3px 10px; border-radius: 12px; font-size: 14px; } .answer { background-color: rgba(255, 255, 255, 0.05); padding: 15px; margin-top: 10px; } .accepted-badge { background-color: var(--accent-primary); color: var(--text-primary); padding: 3px 10px; border-radius: 15px; font-size: 14px; } /* 热度图 */ .heatmap-container { display: grid; grid-template-columns: 1fr; gap: 15px; } .heat-topic { font-weight: 600; margin-bottom: 5px; } .heat-bar { height: 20px; background-color: rgba(255, 255, 255, 0.1); margin: 5px 0; border-radius: 10px; overflow: hidden; } .heat-fill { height: 100%; border-radius: 10px; } /* 话唠榜 */ .participant-rank { font-size: 28px; font-weight: 700; color: var(--accent-primary); margin-right: 15px; float: left; } .participant-name { font-weight: 600; font-size: 18px; margin-bottom: 5px; } .participant-count { color: var(--accent-cyan); margin-bottom: 10px; } .participant-characteristics, .participant-words { display: flex; flex-wrap: wrap; gap: 8px; margin-top: 10px; } .characteristic { background-color: rgba(242, 95, 76, 0.2); padding: 3px 10px; border-radius: 12px; font-size: 14px; } .word { background-color: rgba(229, 49, 112, 0.2); padding: 3px 10px; border-radius: 12px; font-size: 14px; } /* 熬夜冠军 */ .night-owl-item { background: linear-gradient(135deg, #0f0e17 0%, #192064 100%); padding: 20px; display: flex; align-items: center; } .owl-crown { font-size: 40px; margin-right: 20px; } .owl-name { font-weight: 600; font-size: 18px; margin-bottom: 5px; } .owl-title { color: var(--accent-primary); font-style: italic; margin-bottom: 10px; } .owl-time, .owl-messages { color: var(--text-secondary); margin-bottom: 5px; } .owl-note { font-size: 14px; color: var(--text-secondary); margin-top: 10px; font-style: italic; } /* 词云 - 云朵样式 */ .cloud-container { position: relative; margin: 0 auto; padding: 20px 0; } .cloud-wordcloud { position: relative; width: 600px; height: 400px; margin: 0 auto; background-color: var(--bg-tertiary); border-radius: 50%; box-shadow: 40px 40px 0 -5px var(--bg-tertiary), 80px 10px 0 -10px var(--bg-tertiary), 110px 35px 0 -5px var(--bg-tertiary), -40px 50px 0 -8px var(--bg-tertiary), -70px 20px 0 -10px var(--bg-tertiary); overflow: visible; } .cloud-word { position: absolute; transform-origin: center; text-shadow: 0 2px 4px rgba(0, 0, 0, 0.3); transition: all 0.3s ease; } .cloud-word:hover { transform: scale(1.1); z-index: 10; } .cloud-legend { margin-top: 60px; display: flex; justify-content: center; gap: 30px; } .legend-item { display: flex; align-items: center; gap: 10px; } .legend-color { width: 20px; height: 20px; border-radius: 50%; } /* 底部 */ footer { text-align: center; padding: 20px 0; margin-top: 50px; background-color: var(--bg-secondary); color: var(--text-secondary); font-size: 14px; } footer p { margin: 5px 0; } .disclaimer { margin-top: 15px; font-style: italic; } /* 新增头像相关样式 */ .user-avatar { width: 50px; height: 50px; border-radius: 50%; object-fit: cover; transition: transform 0.3s ease; position: relative; cursor: pointer; border: 2px solid var(--accent-primary); } /* 头像悬停效果 */ .user-avatar:hover { transform: scale(1.1) rotate(5deg); z-index: 100; } /* 头像tooltip */ .avatar-tooltip { visibility: hidden; background-color: var(--bg-tertiary); color: var(--text-primary); text-align: center; padding: 5px 10px; border-radius: 6px; position: absolute; z-index: 1000; bottom: 125%; left: 50%; transform: translateX(-50%); white-space: nowrap; opacity: 0; transition: opacity 0.3s; font-size: 14px; box-shadow: 0 3px 10px rgba(0,0,0,0.2); } .user-avatar:hover .avatar-tooltip { visibility: visible; opacity: 1; } /* 热度用户专区 */ .hot-users { display: grid; grid-template-columns: repeat(auto-fit, minmax(80px, 1fr)); gap: 20px; margin-top: 20px; } .hot-user-item { position: relative; text-align: center; } /* 皇冠标识 */ .hot-crown { position: absolute; top: -10px; right: -5px; font-size: 24px; color: #ffd700; filter: drop-shadow(0 2px 2px rgba(0,0,0,0.3)); } </style> </head> <body> <header> <h1>[群/用户名称]日报</h1> <p class="date">[日期]</p> <div class="meta-info"> <span>总消息数:[数量]</span> <span>活跃用户:[数量]</span> <span>时间范围:[时间范围]</span> </div> </header> <!-- 1. 今日讨论热点 --> <section class="hot-topics"> <h2>今日讨论热点</h2> <div class="topics-container"> <!-- 在这里填充讨论热点内容,严格按照以下格式,保留3-5个话题 --> <!-- 在这里填充讨论热点内容 --> <!-- 复制上述卡片结构添加更多话题 --> </div> </section> <!-- 2. 实用教程与资源分享 --> <section class="tutorials"> <h2>实用教程与资源分享</h2> <div class="tutorials-container"> <!-- 在这里填充教程和资源内容,严格按照以下格式 --> <!-- 在这里填充教程和资源内容 --> <!-- 复制上述卡片结构添加更多资源 --> </div> </section> <!-- 3. 重要消息汇总 --> <section class="important-messages"> <h2>重要消息汇总</h2> <div class="messages-container"> <!-- 在这里填充重要消息内容,严格按照以下格式 --> <!-- 在这里填充重要消息内容 --> <!-- 复制上述卡片结构添加更多消息 --> </div> </section> <!-- 4. 有趣对话或金句 --> <section class="interesting-dialogues"> <h2>有趣对话或金句</h2> <div class="dialogues-container"> <!-- 在这里填充对话内容,严格按照以下格式 --> <!-- 在这里填充对话内容 --> <!-- 复制上述卡片结构添加更多对话 --> </div> </section> <!-- 5. 问题与解答 --> <section class="questions-answers"> <h2>问题与解答</h2> <div class="qa-container"> <!-- 在这里填充问答内容,严格按照以下格式 --> <!-- 在这里填充问答内容 --> <!-- 复制上述卡片结构添加更多问答 --> </div> </section> <!-- 6. 群内数据可视化 --> <section class="analytics"> <h2>群内数据可视化</h2> <!-- 话题热度 --> <h3>话题热度</h3> <div class="heatmap-container"> <!-- 在这里填充话题热度数据,严格按照以下格式 --> <!-- 复制上述结构添加更多热度项,每项使用不同颜色 --> <!-- 在这里填充话题热度数据 --> <!-- 可用的颜色: #3da9fc, #f25f4c, #7209b7, #e53170, #00b4d8, #4cc9f0 --> </div> <!-- 话唠榜 --> <!-- 在话唠榜添加头像 --> <section class="analytics"> <h3>话唠榜</h3> <div class="participants-container"> <!-- 在这里填充话唠榜数据 --> </div> </section> <!-- 熬夜冠军 --> <h3>熬夜冠军</h3> <div class="night-owls-container"> <!-- 在这里填充熬夜冠军数据,严格按照以下格式 --> <!-- 在这里填充熬夜冠军内容 --> </div> </section> <!-- 7. 词云 --> <section class="word-cloud"> <h2>热门词云</h2> <div class="cloud-container"> <!-- 词云容器 - 现在是云朵样式 --> <div class="cloud-wordcloud" id="word-cloud"> <!-- 为每个词创建一个span元素,使用绝对定位放置 --> <!-- 以下是一些示例,请根据实际内容生成40-60个词 --> <!-- 在这里填充词云内容 --> <!-- 继续添加更多词 --> </div> <div class="cloud-legend"> <!-- 在这里填充词云分类内容 --> </div> </div> </section> <!-- 8. 页面底部 --> <footer> <p>数据来源:[群名称]聊天记录</p> <p>生成时间:<span class="generation-time">[当前时间]</span></p> <p>统计周期:[日期] [时间范围]</p> <p class="disclaimer">免责声明:本报告内容基于群聊公开讨论,如有不当内容或侵权问题请联系管理员处理。</p> </footer> </body> <script> document.addEventListener('DOMContentLoaded', function() { // 获取所有词云元素 const cloudWords = document.querySelectorAll('.cloud-word'); const container = document.querySelector('.cloud-wordcloud'); const containerWidth = container.offsetWidth; const containerHeight = container.offsetHeight; // 为每个词云元素设置随机位置 cloudWords.forEach(word => { const wordWidth = word.offsetWidth; const wordHeight = word.offsetHeight; // 计算随机位置,确保词云元素不会超出容器边界 const randomLeft = Math.random() * (containerWidth - wordWidth); const randomTop = Math.random() * (containerHeight - wordHeight); // 设置位置 word.style.left = `${randomLeft}px`; word.style.top = `${randomTop}px`; // 添加悬停效果 word.addEventListener('mouseover', function() { this.style.transform = 'scale(1.1)'; this.style.zIndex = '10'; }); word.addEventListener('mouseout', function() { this.style.transform = 'scale(1)'; this.style.zIndex = '1'; }); }); }); </script> </html> """ json_data = json_data[7:-3] # 清洗json_data # 判断是否是转义的换行符 if '\n' in json_data: json_data = json_data.replace('\n', '\n') else: json_data = json_data.replace(r'\"','"').replace(r"\n",'\n') # print(json_data) # 使用正则表达式查找json字符串 pattern = re.compile('{.*}', flags=re.IGNORECASE | re.MULTILINE | re.S) print(pattern.search(json_data).group()) json_data = json.loads(pattern.search(json_data).group()) # json_data = json.loads(json_data) # print(json_data) # print(json.dumps(json_data,indent=4, ensure_ascii=False)) # 替换头部信息 header = json_data['header'] html = html.replace('[群/用户名称]日报', f"{header['title']}报告") html = html.replace('[日期]', header['date']) html = html.replace('总消息数:[数量]', f"总消息数:{header['metaInfo']['totalMessages']}") html = html.replace('活跃用户:[数量]', f"活跃用户:{header['metaInfo']['activeUsers']}") html = html.replace('时间范围:[时间范围]', f"时间范围:{header['metaInfo']['timeRange']}") # 处理热点话题 hot_topics = [] for topic in json_data['sections']['hotTopics']['items']: keywords = ''.join([f'<span class="keyword">{kw}</span>' for kw in topic['keywords']]) hot_topics.append(f""" <div class="topic-card"> <h3>{topic['name']}</h3> <div class="topic-category">{topic['category']}</div> <p class="topic-summary">{topic['summary']}</p> <div class="topic-keywords"> {keywords} </div> <div class="topic-mentions">提及次数:{topic['mentions']}</div> </div>""") html = html.replace('<!-- 在这里填充讨论热点内容 -->', '\n'.join(hot_topics)) # 处理教程资源 tutorials = [] for tut in json_data['sections']['tutorials']['items']: points = ''.join([f'<li>{p}</li>' for p in tut['keyPoints']]) tutorials.append(f""" <div class="tutorial-card"> <div class="tutorial-type">{tut['type']}</div> <h3>{tut['title']}</h3> <div class="tutorial-meta"> <span class="shared-by">分享者:{tut['sharedBy']}</span> <span class="share-time">时间:{tut['time']}</span> </div> <p class="tutorial-summary">{tut['summary']}</p> <div class="key-points"> <h4>要点:</h4> <ul>{points}</ul> </div> <div class="tutorial-link"> <a href="{tut['url']}" class="link valid">查看原文: {tut['domain']}</a> </div> <div class="tutorial-category">分类:{tut['category']}</div> </div>""") html = html.replace('<!-- 在这里填充教程和资源内容 -->', '\n'.join(tutorials)) # 处理重要消息 messages = [] for msg in json_data['sections']['importantMessages']['items']: messages.append(f""" <div class="message-card"> <div class="message-meta"> <span class="time">{msg['time']}</span> <span class="sender">{msg['sender']}</span> <span class="message-type">{msg['type']}</span> <span class="priority priority-{msg['priority']}">优先级:{msg['priority']}</span> </div> <p class="message-content">{msg['content']}</p> <div class="message-full-content"> <p>{msg['fullContent']}</p> </div> </div>""") html = html.replace('<!-- 在这里填充重要消息内容 -->', '\n'.join(messages)) # 处理对话 dialogues = [] for dia in json_data['sections']['dialogues']['items']: messages = ''.join([f""" <div class="message"> <div class="message-meta"> <span class="speaker">{m['speaker']}</span> <span class="time">{m['time']}</span> </div> <p class="message-content">{m['content']}</p> </div>""" for m in dia['messages']]) dialogues.append(f""" <div class="dialogue-card"> <div class="dialogue-type">{dia['type']}</div> <div class="dialogue-content"> {messages} </div> <div class="dialogue-highlight">{dia['highlight']}</div> <div class="dialogue-topic">相关话题:{dia['relatedTopic']}</div> </div>""") html = html.replace('<!-- 在这里填充对话内容 -->', '\n'.join(dialogues)) # 处理问答 qas = [] for qa in json_data['sections']['qa']['items']: tags = ''.join([f'<span class="tag">{tag}</span>' for tag in qa['question']['tags']]) answers = ''.join([f""" <div class="answer"> <div class="answer-meta"> <span class="responder">{ans['responder']}</span> <span class="time">{ans['time']}</span> {"<span class='accepted-badge'>最佳回答</span>" if ans['isAccepted'] else ""} </div> <p class="answer-content">{ans['content']}</p> </div>""" for ans in qa['answers']]) qas.append(f""" <div class="qa-card"> <div class="question"> <div class="question-meta"> <span class="asker">{qa['question']['asker']}</span> <span class="time">{qa['question']['time']}</span> </div> <p class="question-content">{qa['question']['content']}</p> <div class="question-tags"> {tags} </div> </div> <div class="answers"> {answers} </div> </div>""") html = html.replace('<!-- 在这里填充问答内容 -->', '\n'.join(qas)) # 处理数据可视化 heatmap = [] colors = ['#3da9fc', '#f25f4c', '#7209b7', '#e53170', '#00b4d8', '#4cc9f0'] for i, topic in enumerate(json_data['sections']['analytics']['heatmap']): color = colors[i % len(colors)] heatmap.append(f""" <div class="heat-item"> <div class="heat-topic">{topic['topic']}</div> <div class="heat-percentage">{topic['percentage']}%</div> <div class="heat-bar"> <div class="heat-fill" style="width: {topic['percentage']}%; background-color: {color};"></div> </div> <div class="heat-count">{topic['count']}条消息</div> </div>""") html = html.replace('<!-- 在这里填充话题热度数据 -->', '\n'.join(heatmap)) # 处理话唠榜 chatty = [] for rank in json_data['sections']['analytics']['chattyRanking']: words = ''.join([f'<span class="word">{w}</span>' for w in rank['commonWords']]) characteristics = ''.join([f'<span class="characteristic">{c}</span>' for c in rank['characteristics']]) chatty.append(f""" <div class="participant-item"> <div class="participant-rank">{rank['rank']}</div> <div class="participant-info"> <div class="participant-name">{rank['name']}</div> <div class="participant-count">发言数:{rank['count']}</div> <div class="participant-characteristics"> {characteristics} </div> <div class="participant-words"> {words} </div> </div> </div>""") html = html.replace('<!-- 在这里填充话唠榜数据 -->', '\n'.join(chatty)) # 处理熬夜冠军 nightOwl = json_data['sections']['analytics']['nightOwl'] f = f""" <div class="night-owl-item"> <div class="owl-crown" title="熬夜冠军">👑</div> <div class="owl-info"> <div class="owl-name">{nightOwl['name']}</div> <div class="owl-title">{nightOwl['title']}</div> <div class="owl-time">最晚活跃时间:{nightOwl['latestTime']}</div> <div class="owl-messages">深夜消息数:{nightOwl['messageCount']}</div> <div class="owl-last-message">{nightOwl['lastMessage']}</div> <div class="owl-note">注:熬夜时段定义为23:00-06:00,已考虑不同时区</div> </div>""" html = html.replace('<!-- 在这里填充熬夜冠军内容 -->','\n' + f + '\n') # 处理词云 words = [] for word in json_data['sections']['wordCloud']['words']: words.append(f""" <span class="cloud-word" style="left: {word.get('x', 300)}px; top: {word.get('y', 120)}px; font-size: {word['size']}px; color: {word['color']}; transform: rotate({word['rotation']}deg);">{word['text']}</span>""") html = html.replace('<!-- 在这里填充词云内容 -->', '\n'.join(words)) # 处理词云的分类 types = [] for typ in json_data['sections']['wordCloud']['legend']: types.append(f""" <div class="legend-item"> <span class="legend-color" style="background-color: {typ['color']};"></span> <span class="legend-label">{typ['label']}</span> </div> """ ) html = html.replace('<!-- 在这里填充词云分类内容 -->', '\n'.join(types)) # 处理页脚 footer = json_data['footer'] html = html.replace('[群名称]', footer['dataSource']) html = html.replace('[当前时间]', footer['generationTime']) html = html.replace('[日期] [时间范围]', footer['statisticalPeriod']) return {'result':html}打开
失败时重试,并设置次数为三次(几次都可以,三次就够了)。
添加
结束节点,设置变量。
至此,dify工作流开发完毕。
可以点击右上角进行
发布使用。
使用
首先需要导出聊天记录,可以参考另一篇文章里面的部分教程(我二开的一个工具,还能直接全自动生成可视化页面):全自动实现微信聊天记录可视化AI工具 - 秦绍鹏的笔记。
使用导出后的文件内容,上传到工作流,之后就能生成相应的结果了。
总结
总的来说,这个工作流开发不算太难,只不过里面的一些提示词和代码是经过我自己优化了的。最终生成的可视化页面的模板是依靠知乎文章用AI把微信聊天记录变成可视化报告,酷到封神。 - 知乎 其中的html代码。但是经过我自己的优化又再次使用的。